
部署Ollama
拉取镜像
docker pull ollama/ollama创建持久化目录
mkdir -p /data/ollama启动容器
docker run -d -v /data/ollama:/root/.ollama -p 11434:11434 --name ollama --restart always ollama/ollama部署完成后就可以通过本机IP+11434端口访问Ollama了,不过通过webui访问更方便一些,所以接下部署WebUI
部署WebUI
拉取镜像
docker pull ghcr.nju.edu.cn/open-webui/open-webui:main创建持久化目录
mkdir -p /data/open-webui启动容器
#中间IP位置要替换成Ollama所在IP
docker run -d -p 8080:8080 -e OLLAMA_BASE_URL=http://${Ollama_ip}:11434 -v /data/open-webui:/app/backend/data --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main启动容器稍等一会,也可以通过命令查看日志,当输出下面界面时就已经启动完成
docker logs -f open-webui --tail 100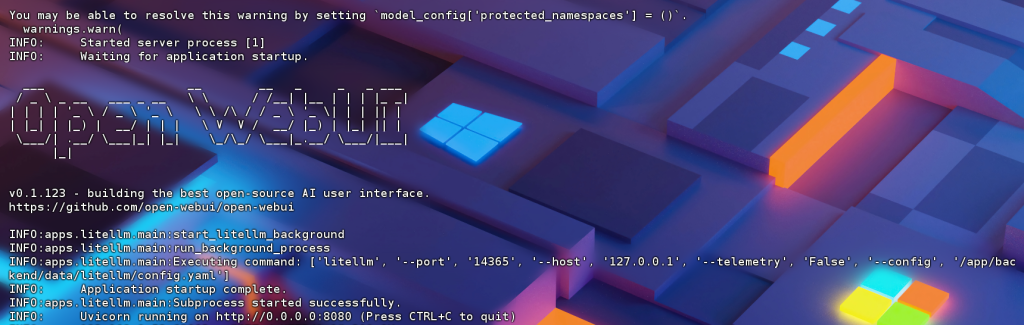
接着访问IP+8080打开web界面,注册并登陆后默认显示英文界面,可以在设置里调整成中文
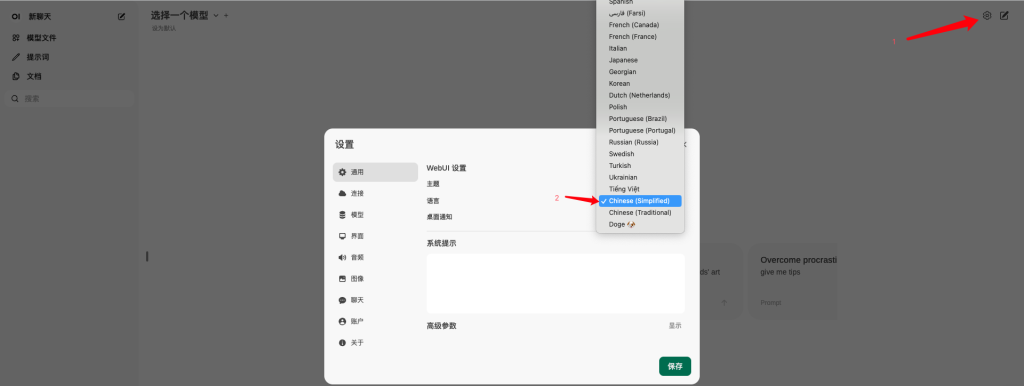
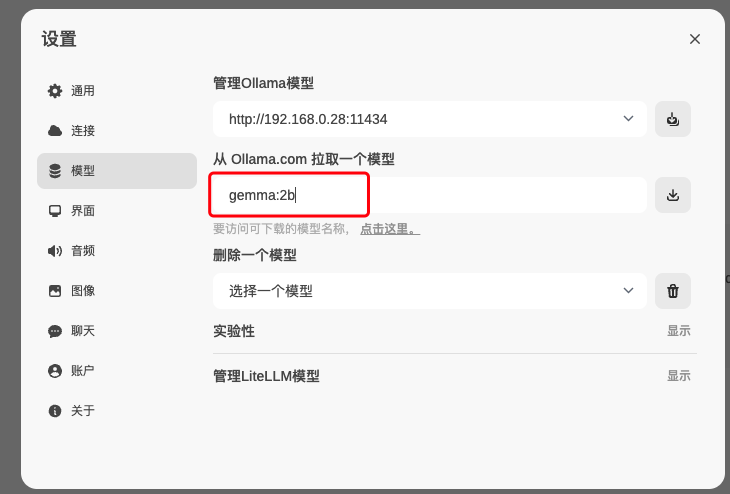
接下来要下载语言模型,可以通过web界面下载,也可以通过命令下载
#命令方式
docker exec -it ollama ollama run c "hello"web界面下载
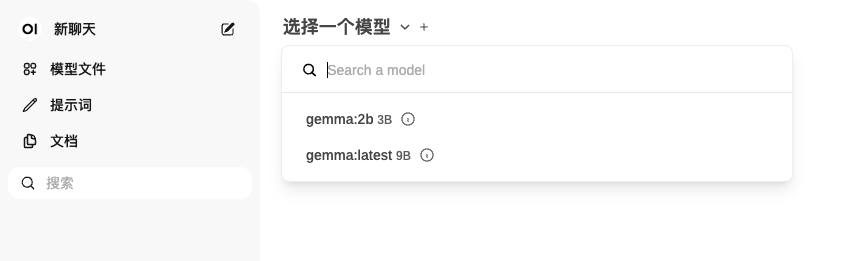
模型下载完成后就可以和Ai聊天了,要先选择模型再进行提问
到这里本地语言模型就部署完成了,这些模型一般都比较吃CPU运算,如果本地有GPU较强的电脑也可以通过GPU进行运算,初始化时候调整命令就可以了,在搜索引擎搜一下应该很多,我这里就不提示了。